ChatGPT Atlas vs Google (Gemini in Chrome): A Quick Browser Benchmark You Can Actually Run
I ran a small, practical test of browser tasks: summaries, fact checks, and multi-step jobs. I also ran human-rated tests on the Faila story from my blog and added those results below.

Why I Did This
A new browser-first tool called ChatGPT Atlas hit the market. The pitch is simple: an assistant that lives in the browser and works directly with web pages. That sounds cool. But is it actually better than the tools we already use, like Google’s Gemini in Chrome?
I wanted a real-world answer. So I ran the same tasks in both systems. No lab-grade claims. Just usable tests you can repeat.
What I Tested
I ran three types of tests to see how each tool handles real browser work:
Summaries: I gave both systems web articles and asked them to create short bullet summaries with a headline. This tests how well they extract key points and present them clearly.
Factual Q&A: I asked them to pull exact names, dates, and numbers from web pages. This is the strictest test: either the tool gets the fact right or it doesn’t. No room for creative interpretation.
Agentic tasks: These are multi-step jobs where the tool needs to synthesize information across pages, compare different sources, and give actionable next steps. This tests whether they can actually “think” beyond simple extraction.
For one specific test, I also used content from my own blog to see how each tool would handle it when I know exactly what the source material says.
Short Verdict
Both systems are good.
Atlas was a bit safer on strict fact extraction in these runs.
Gemini in Chrome produced summaries people liked slightly more.
Both handled the technical analysis well.
The Numbers (Simple Table)
Here are the means from the runs I used. I rounded to three decimals where it helps.
| system | task | runs | avg latency ms | citation correctness | factual accuracy | helpfulness | faithfulness |
|---|---|---|---|---|---|---|---|
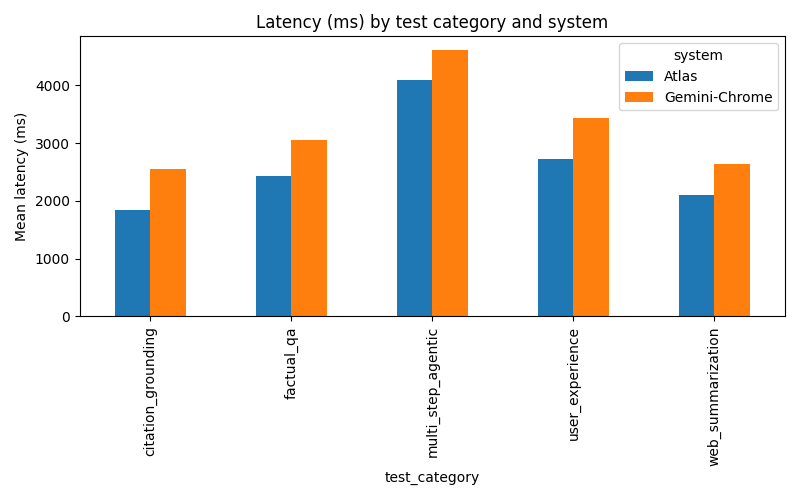
| Atlas | web summarization | 11 | 2098 | 0.855 | 0.854 | 4.176 | 4.086 |
| Gemini-Chrome | web summarization | 11 | 2647 | 0.880 | 0.864 | 4.468 | 4.080 |
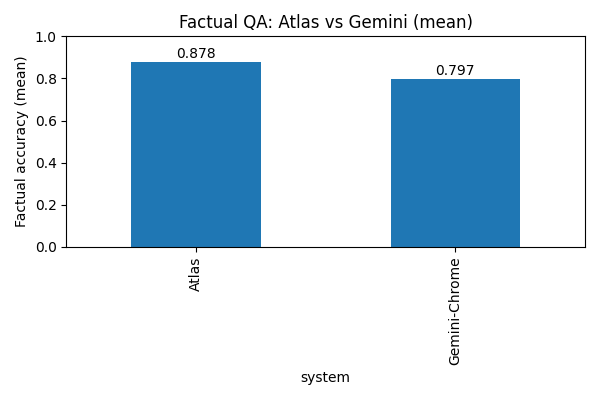
| Atlas | factual QA | 5 | 2431 | 0.879 | 0.878 | - | - |
| Gemini-Chrome | factual QA | 5 | 3052 | 0.801 | 0.797 | - | - |
| Atlas | multi-step agentic | 2 | 4095 | 0.871 | 0.872 | 4.403 | 4.209 |
| Gemini-Chrome | multi-step agentic | 2 | 4619 | 0.901 | 0.900 | 4.532 | 4.708 |
Notes:
-means that metric was not recorded for that task in the CSV.- Latency includes browser UI overhead, so treat it as perceived speed, not raw model time.
Testing on My Own Content: The Faila Story
To add a focused, human-rated check with content I knew inside and out, I used one of my own blog posts: The Day a Name Stopped Billing.
This is a technical story about a subscriber name (“Faila”) that broke a telecom billing system because it contained the substring “FAIL.” I know exactly what happened, what the lesson was, and how it’s written. That made it a perfect test case to see if these tools could accurately summarize technical content and identify root causes.
I asked both systems to:
- Summarize the article
- Explain the technical root cause and suggest fixes
Here are the human-rated results from those test runs:
| Task | System | Latency (ms) | Helpfulness | Faithfulness | Clarity | Trust |
|---|---|---|---|---|---|---|
| Summarize Faila article | Atlas | 2629 | 4.0 | 4.0 | 5.0 | 5.0 |
| Summarize Faila article | Gemini-Chrome | 2603 | 4.0 | 5.0 | 5.0 | 5.0 |
| Tech root-cause + fixes | Atlas | 2217 | 5.0 | 5.0 | 5.0 | 5.0 |
| Tech root-cause + fixes | Gemini-Chrome | 2608 | 5.0 | 5.0 | 5.0 | 5.0 |
Quick takeaways from that tiny sample:
- Both systems produced clear, useful summaries. Raters gave Gemini a small edge on faithfulness for this article.
- For the technical analysis both systems scored perfect 5/5 across human metrics in this run.
- Remember: this is one article and a small number of ratings. It’s a signal, not proof.
What I Think This Actually Means
Keep it simple:
If you need exact facts and numbers, Atlas looked a bit safer in these runs. It had higher factual-accuracy means on the factual QA tests.
If you want a quick, reader-ready summary that sounds good out of the box, Gemini often produces more polished prose and humans liked that here.
For multi-step jobs both do the work. Differences are mostly style and how they show their steps.
Caveats (And What to Watch If You Run This Yourself)
If you decide to run a similar benchmark yourself, keep in mind a few problems:
Small sample sizes. Some of these tests only had 2-5 runs. Increase N if you want statistical confidence. What I’m showing here are signals, not proof.
Human ratings need more raters. I used the interactive runs for ratings. For solid results, get 3+ independent raters for each response.
Latency is fuzzy. My numbers include UI and automation overhead. Don’t treat them as pure server speed. Your mileage will vary based on your setup and network.
Prompts matter a lot. Keep your prompts identical across systems when you compare. Small wording changes can shift results.
Page choice matters too. Different content types (news, technical docs, product pages) may favor one system over another. Test on content similar to what you’ll actually use.
Visuals and Raw Data (For the Nerds)
I generated simple charts from the test runs. Here are the key visualizations:
Factual Accuracy by System and Category:
Latency by System and Category:
Raw Data:
If you want to verify the results or run your own analysis, you can download the raw data:
Related Reading
If you enjoyed this deep dive into AI tools, check out my AI in Coding series:
- AI in Coding, Part 1: From LISP Dreams to GitHub Copilot Reality
- AI in Coding, Part 2: AI Tools Every Engineer Should Know in 2025
- AI in Coding, Part 3: Best Practices for Working with Your New Junior Developer
- AI in Coding, Part 4: Building a Modern Web App Live With AI
- AI in Coding, Part 5: How Far We’ve Come in Just 3 Years
- AI in Coding, Part 6: The Next 10 Years of Software Development
- AI in Coding, Part 7: Will AI Replace Programmers? Looking 20–40 Years Ahead
- AI in Coding, Part 8: Future-Proofing Your Career in the AI Era
And if you haven’t read the Faila story that I used for testing, check it out:

Irhad Babic
Practical insights on engineering management, AI applications, and product building from a hands-on engineering leader and manager.


